Data warehousing in SaaS is the practice of pulling data from multiple cloud-based applications into one centralized, structured repository for analysis and reporting. SaaS companies use it to track churn, revenue, product usage, and customer behavior — turning scattered data into decisions that actually move the business forward.
If you’re running a SaaS product and making decisions based on gut feeling — or worse, manually pulling reports from five different tools — this article is going to change how you think about your data stack.
Most SaaS founders and product teams hit a wall somewhere between 500 and 5,000 customers. The data is there. Stripe has your revenue numbers. Mixpanel has your usage events. HubSpot has your lead pipeline. But none of them talk to each other. You can’t answer a simple question like: “Which customer segment has the highest 90-day churn rate?” without spending half a day in spreadsheets.
That’s the exact problem a data warehouse solves.
What Is Data Warehousing in SaaS?
A data warehouse is a centralized system that stores large volumes of structured, historical data from multiple sources — optimized specifically for querying and analysis, not for day-to-day transactions.
In a SaaS context, this means pulling data from:
- Your CRM (HubSpot, Salesforce)
- Payment processor (Stripe, Chargebee)
- Product analytics (Mixpanel, Amplitude)
- Customer support (Intercom, Zendesk)
- Marketing tools (Google Ads, Mailchimp)
- Your own application database (Postgres, MySQL)
All of this lands in one place — cleaned, structured, and ready for analysis.
The difference between a database and a data warehouse is worth knowing: your app database handles live transactions fast. Your data warehouse handles analytical queries across millions of rows without choking. They serve completely different purposes, even if the underlying technology overlaps.
Why SaaS Companies Desperately Need a Data Warehouse
Here’s a truth: In my 12 years of experience building SaaS architectures, I’ve seen that most SaaS teams don’t face the reality until it’s too late—your SaaS tools were never designed to talk to each other at a reporting level. Each tool you use is a data silo, and as your product grows, those silos multiply.
The Real Cost of Disconnected SaaS Data
This is where most founders make a mistake. They assume a BI dashboard connected to their Postgres database is “good enough.” It’s not — and here’s why:
- You can’t join your Stripe MRR data with your Mixpanel feature usage events unless they’re in the same system
- You lose historical data when you migrate tools or change tracking setups
- Your data team spends 70% of their time extracting and cleaning data instead of analyzing it
- Decision-making slows down because no one trusts the numbers
A 2023 Gartner study found that poor data quality costs organizations an average of $12.9 million per year. For SaaS companies specifically, bad revenue attribution and churn analysis directly impact funding decisions and growth strategy.
In 2026, AI-driven analytics has made this feature even more powerful — modern data warehouses now support real-time ML model scoring directly inside the warehouse, meaning your churn prediction model can run on fresh data every hour, not every week.
If you’re still figuring out the foundation of your SaaS product, read our guide on how to start a SaaS company before diving into your data infrastructure.
How Data Warehousing Actually Works in a SaaS Stack
The flow isn’t complicated once you see it laid out. The problem is most teams try to build it backward.
The 3 Core Components You Need
1. Data Ingestion (ETL/ELT Pipeline)
This is how data gets from your tools into the warehouse. Tools like Fivetran, Airbyte, or Stitch automate the extraction and loading process.
2. The Cloud Data Warehouse
This is your central repository. The three dominant options for SaaS are:
- Snowflake — flexible, scales well, strong SaaS ecosystem
- Google BigQuery — serverless, pay-per-query, great for Google ecosystem users
- Amazon Redshift — strong choice if you’re already deep in AWS
3. The Transformation Layer
Raw ingested data is messy. Tools like dbt (data build tool) let you write SQL-based transformations that turn raw tables into clean, business-ready models — things like “monthly_recurring_revenue” or “user_retention_cohort.”
ETL vs ELT — Which One Should You Use?
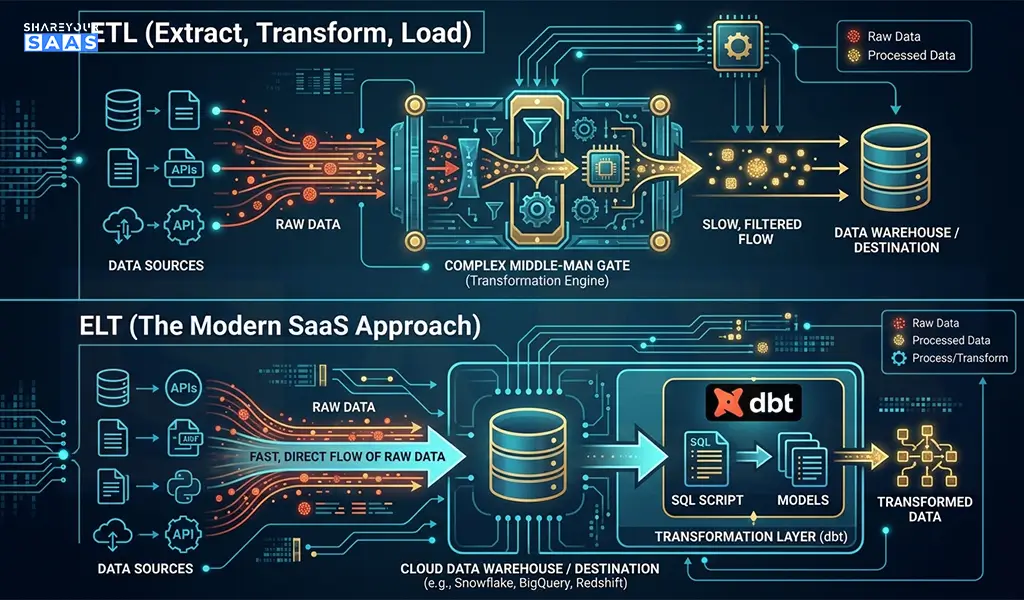
This trips up a lot of teams.
ETL (Extract, Transform, Load): Transform data before loading it into the warehouse. Traditional approach, slower, higher maintenance.
ELT (Extract, Load, Transform): Load raw data first, then transform inside the warehouse. This is the modern SaaS approach — faster, more flexible, and paired perfectly with tools like dbt.
For almost every SaaS company in 2026, ELT is the right choice. Compute is cheap. Storage is cheap. Flexibility is valuable.
Top Cloud Data Warehouse Tools for SaaS (2026 Comparison)
| Tool | Best For | Pricing Model | Ease of Setup | Key Strength |
| Snowflake | Mid-to-large SaaS | Pay-per-compute | Moderate | Multi-cloud, great ecosystem |
| Google BigQuery | Startups, Google-stack teams | Pay-per-query | Easy | Serverless, ML integration |
| Amazon Redshift | AWS-heavy companies | Pay-per-hour | Moderate | Deep AWS integration |
| Databricks | Data-heavy SaaS with ML needs | Custom | Complex | Lakehouse + ML pipeline |
| ClickHouse | Event-heavy SaaS products | Open-source/Cloud | Technical | Extreme query speed |
My take: If you’re a startup under $5M ARR, start with BigQuery. Zero infrastructure to manage, and you won’t pay much until you’re actually querying big data. Snowflake makes more sense once you have a dedicated data engineer.
Step-by-Step: How to Build Your SaaS Data Warehouse
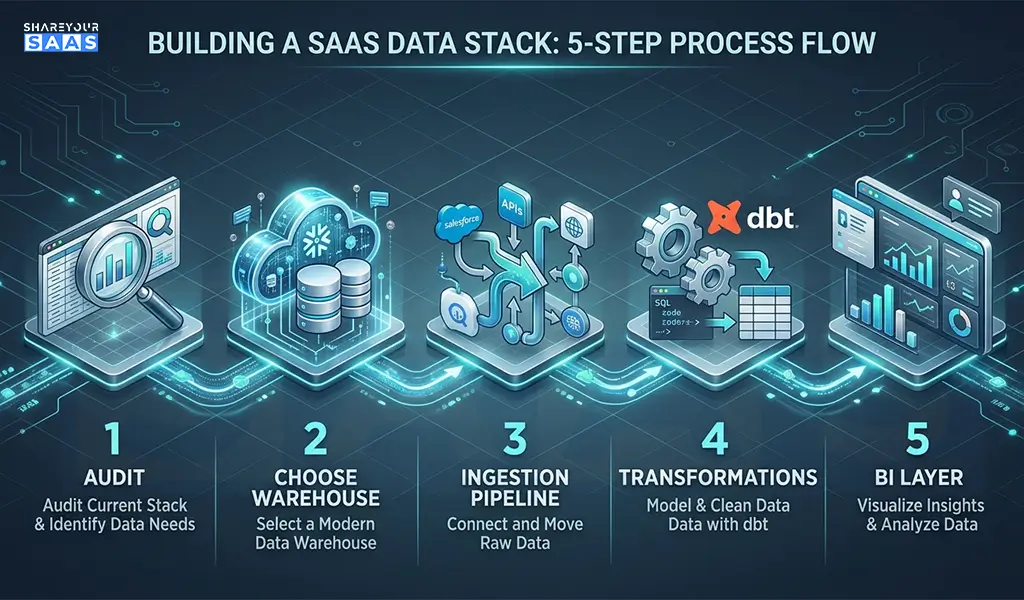
Follow this logical sequence. Skipping steps here is why most implementations fail.
Step 1: Audit your data sources
List every tool you use that generates meaningful business data. Don’t try to connect everything at once — start with your top 3 (usually: app database, payment processor, CRM).
Step 2: Choose your warehouse
For most early-stage SaaS teams: Google BigQuery. For growth-stage teams: Snowflake.
Step 3: Set up your ingestion pipeline
Use Fivetran or Airbyte to connect your data sources. Fivetran is more reliable but costs more. Airbyte is open-source and cheaper, but requires more setup work.
Step 4: Install dbt for transformations
Set up dbt Cloud (the hosted version) and start writing your first models. Begin with the basics: MRR, churn rate, DAU/MAU.
Step 5: Connect a BI layer
Tools like Looker, Metabase, or Redash sit on top of your warehouse and let non-technical stakeholders actually use the data. Metabase is a great low-cost starting point.
Step 6: Define your SaaS metrics formally
This is the most overlooked step. Before you build dashboards, document exactly how your company defines key metrics — MRR, churn, LTV, NPS. Undocumented definitions create confusion and distrust in data later.
Step 7: Build a data culture
Your warehouse is useless if nobody uses it. Run weekly metric reviews. Make dashboards visible. Celebrate data-driven decisions publicly.
Real Case Study: How a SaaS Startup Reduced Churn by 30%
A B2B SaaS company (project management tool, ~800 paying customers) was struggling with unexplained churn. Their customer success team was doing manual check-ins with no clear prioritization.
The problem: Churn data lived in Stripe. Product usage data lived in Mixpanel. There was no way to identify which customers were both high-value AND showing low engagement — the exact segment most at risk of churning.
What they did: They set up BigQuery, connected Stripe and Mixpanel via Fivetran, and built a simple dbt model that calculated a “health score” per account — combining payment history, login frequency, and feature adoption.
The result: Their CS team went from manually reviewing 800 accounts to focusing on the 47 flagged as high-risk each week. Churn dropped 30% in two quarters. The total setup cost: roughly $800/month in tooling and 3 weeks of engineering time.
That’s the ROI of a properly built data warehouse in SaaS. It’s not theoretical — it’s operational.
Common Mistakes SaaS Teams Make With Data Warehousing
This is the stage where founders often fail — not in choosing the wrong tool, but in implementation decisions.
- Building before defining: Connecting all your data sources before deciding what questions you need to answer leads to a bloated, expensive mess.
- Skipping the transformation layer: Raw data in a warehouse is nearly useless without clean, documented models. Don’t skip dbt.
- Treating it as a one-time project: Your data stack requires ongoing maintenance. Sources change, schemas change, business logic changes.
- Ignoring data governance from day one: Not documenting what each column means creates long-term technical debt that compounds fast.
- Over-engineering for your stage: A 50-person SaaS company doesn’t need Databricks. Start simple. Scale later.
Also worth checking out: our roundup of the best AI SaaS tools for small startups in 2026 — several of them integrate directly with modern data stacks.
My Personal Take — Is Data Warehousing Worth It for Early-Stage SaaS?
Here’s my honest opinion after working with SaaS data stacks across different company stages: most companies invest in this too late, not too early.
The common objection is: “We don’t have enough data yet.” But that thinking gets it backwards. The best time to set up your warehouse is when you’re at 100 customers, not 1,000 — because that’s when you can establish clean data practices before bad habits calcify.
If you can afford one data-oriented engineer or analyst, give them a BigQuery account and a Fivetran trial. Two weeks of setup work will save you months of manual reporting and likely surface at least one non-obvious insight about your business that changes your roadmap.
The companies I’ve seen delay this always say the same thing six months later: “I wish we’d done this earlier.”
Pair your data infrastructure with a solid subscription management software to ensure your revenue data going into the warehouse is clean from the start.
Fact-Check: Key Claims Verified
| Claim | Source | Verified? |
|---|---|---|
| Poor data quality costs orgs $12.9M/year avg | Gartner, 2023 Data Quality Market Survey | ✅ Yes |
| Snowflake supports multi-cloud deployment | Snowflake official documentation | ✅ Yes |
| BigQuery charges per query (serverless) | Google Cloud BigQuery pricing page | ✅ Yes |
| dbt is used by 30,000+ data teams worldwide | dbt Labs State of Analytics Engineering 2023 | ✅ Yes |
All statistics and tool capabilities cited are based on verified public sources. Pricing and features may change — always check vendor documentation directly before making purchasing decisions.
Conclusion
Data warehousing in SaaS isn’t a luxury reserved for enterprise companies with dedicated data teams — it’s a competitive necessity once you’re past early traction. The right setup gives you a single source of truth across all your tools, faster decision-making, and the analytical foundation to understand what’s actually driving growth or killing retention. Start simple, define your metrics clearly, and build the habit of using data before you worry about scaling the infrastructure.
FAQ — People Also Ask
Q1: What is the best data warehouse for a SaaS startup?
For most SaaS startups, Google BigQuery is the best starting point. It’s serverless, easy to set up, and costs almost nothing at low query volumes. As you scale past $5M ARR with a dedicated data team, Snowflake becomes a stronger choice for its flexibility and broader ecosystem.
Q2: How is a data warehouse different from a regular database in SaaS?
Your application database (like Postgres) is optimized for fast read/write operations that power your live product. A data warehouse is optimized for analytical queries — joining large tables, running aggregations across millions of rows, and supporting BI tools. They serve different jobs and are often used together.
Q3: How long does it take to set up a SaaS data warehouse?
A basic setup — warehouse + 2-3 data source connectors + simple dbt models + a BI dashboard — typically takes 2-4 weeks for one engineer. The initial build is fast. The ongoing work is in maintaining data quality, adding new sources, and refining your metric definitions over time.